
Oxidizing Lagrange Polynomials for Machine Learning
Table of Contents

Photo by Jay Heike on Unsplash
In recent years, machine learning techniques popolarized well known algorithms like linear regression, even if in a larger data context. Polynomial regression is one of these examples.
In the past, researchers were defing formulae upfront and then regression was applied to fit model parameters. The machine learning approach in this case consists of using the data to evaluate which degree of the polynomial does best fit the observations without overfitting.
The code for this post is available here and is connected with a previous post Polynomials ring
If you see any error or woud like to suggest a more efficient implementation, please let me know in the comments
What are Lagrange Polynomials
Lagrange polynomials are used to find an interpolate monovariate polynomial (i.e. a polynomial of a single variable only).
Given a list x of n points in R (we will call them nodes from now on) and a list y of real values associated with them it is possible to find at least one polynomial of degree n – 1 passing through them.
The problem is equivalent to the following linear problem
![\left[ \begin{matrix} 1 & x_1 & x^2_1 & \dots & x^{n-1}_1 \\ 1 & x_2 & x^2_2 & \dots & x^{n-1}_2 \\ \dots \\ 1 & x_n & x^2_n & \dots & x^{n-1}_n \\ \end{matrix} \right] \times \left[ \begin{matrix} a_0 \\ a_1 \\ \dots \\ a_{n-1} \\ \end{matrix} \right] = \left[ \begin{matrix} y_0 \\ y_1 \\ \dots \\ y_{n-1} \\ \end{matrix} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Bmatrix%7D+1+%26+x_1+%26+x%5E2_1+%26+%5Cdots+%26+x%5E%7Bn-1%7D_1+%5C%5C+1+%26+x_2+%26+x%5E2_2+%26+%5Cdots+%26+x%5E%7Bn-1%7D_2+%5C%5C+%5Cdots+%5C%5C+1+%26+x_n+%26+x%5E2_n+%26+%5Cdots+%26+x%5E%7Bn-1%7D_n+%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+%5Ctimes+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+a_0+%5C%5C+a_1+%5C%5C+%5Cdots+%5C%5C+a_%7Bn-1%7D+%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+y_0+%5C%5C+y_1+%5C%5C+%5Cdots+%5C%5C+y_%7Bn-1%7D+%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D++++&bg=ffffff&fg=000&s=0&c=20201002)
The lagrange Polynomial base (denoted here by ![l_i[x]](https://s0.wp.com/latex.php?latex=l_i%5Bx%5D&bg=ffffff&fg=000&s=0&c=20201002)
![I \times \left[ \begin{matrix} b_0 \\ b_1 \\ \dots \\ b_{n-1} \\ \end{matrix} \right] = \left[ \begin{matrix} y_0 \\ y_1 \\ \dots \\ y_{n-1} \\ \end{matrix} \right]](https://s0.wp.com/latex.php?latex=I+%5Ctimes+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+b_0+%5C%5C+b_1+%5C%5C+%5Cdots+%5C%5C+b_%7Bn-1%7D+%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Bmatrix%7D+y_0+%5C%5C+y_1+%5C%5C+%5Cdots+%5C%5C+y_%7Bn-1%7D+%5C%5C+%5Cend%7Bmatrix%7D+%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002)
so the solution becomes
![P[x] = \sum_{i}b_i l_i[x] = \sum_{i}y_i l_i[x]](https://s0.wp.com/latex.php?latex=P%5Bx%5D+%3D+%5Csum_%7Bi%7Db_i+l_i%5Bx%5D+%3D+%5Csum_%7Bi%7Dy_i+l_i%5Bx%5D+&bg=ffffff&fg=000&s=0&c=20201002)
Each polynomial is designed so to have roots in all nodes but one; in that node it will be equal to 1
Here is a simple example: suppose we have oly two nodes in 0 and 1: the Lagrange polynomial base will be composed of the follwing:
![P_0[x] = 1 - x](https://s0.wp.com/latex.php?latex=P_0%5Bx%5D+%3D+1+-+x+&bg=ffffff&fg=000&s=0&c=20201002)
![P_1[x] = x](https://s0.wp.com/latex.php?latex=P_1%5Bx%5D+%3D+x+&bg=ffffff&fg=000&s=0&c=20201002)

if we have say 

![P[x] = 1 * P_0[x] + 3 * P_1[x] = (1 - x) + 3x = 2x + 1](https://s0.wp.com/latex.php?latex=P%5Bx%5D+%3D+1+%2A+P_0%5Bx%5D+%2B+3+%2A+P_1%5Bx%5D+%3D+%281+-+x%29+%2B+3x+%3D+2x+%2B+1+&bg=ffffff&fg=000&s=0&c=20201002)
In the same way if the nodes are placed in -1, 0 and 1 we have:
![P_{-1}[x] = \frac{1}{2} x (x-1)](https://s0.wp.com/latex.php?latex=P_%7B-1%7D%5Bx%5D+%3D+%5Cfrac%7B1%7D%7B2%7D+x+%28x-1%29+&bg=ffffff&fg=000&s=0&c=20201002)
![P_0[x] = -1 (x+1)(x-1)](https://s0.wp.com/latex.php?latex=P_0%5Bx%5D+%3D+-1+%28x%2B1%29%28x-1%29+&bg=ffffff&fg=000&s=0&c=20201002)
![P_1[x] = \frac{1}{2} (x+1) x](https://s0.wp.com/latex.php?latex=P_1%5Bx%5D+%3D+%5Cfrac%7B1%7D%7B2%7D+%28x%2B1%29+x+&bg=ffffff&fg=000&s=0&c=20201002)

Why should Lagrange Polynomials matter in Machine Learning
polynomial regression is a typical example of how machine learning instructed existing knowledge.
While polynomial fitting is a well known application of linear regression, the introduction of concepts such overfitting, regularization, validation etc. clarified greatly how to better use these tools.
As these are iterative approaches, they require a repeated evaluation of the fitting weights; thus any way to make this calculation faster can greatly impact in the overall efficiency of the process.
As lagrange polynomials provide an efficient space base to perform these calculations this approach can have a great application
Let’s set an example context: suppose we have a large number of samples of the form 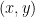


We may want to partition the range where 


![\sigma_i = (\delta (i-1) + min(x), \delta i + min(x)]](https://s0.wp.com/latex.php?latex=%5Csigma_i+%3D+%28%5Cdelta+%28i-1%29+%2B+min%28x%29%2C+%5Cdelta+i+%2B+min%28x%29%5D+&bg=ffffff&fg=000&s=0&c=20201002)

In each 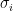


in our example that would be

The starting value in the 

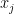

![\bar{y_i} = E_{x_j \in \sigma_i}[y_j]](https://s0.wp.com/latex.php?latex=%5Cbar%7By_i%7D+%3D+E_%7Bx_j+%5Cin+%5Csigma_i%7D%5By_j%5D+&bg=ffffff&fg=000&s=0&c=20201002)
The error evaluation would then be
![\epsilon = \sum_{j}{err(y_j-P[x_j])}](https://s0.wp.com/latex.php?latex=%5Cepsilon+%3D+%5Csum_%7Bj%7D%7Berr%28y_j-P%5Bx_j%5D%29%7D+&bg=ffffff&fg=000&s=0&c=20201002)
where the function 

Let’s assume

and let’s also assume the lagrange polynomial with the initial values
![P[x] = \sum_{i}\bar{y}_i l_i[x]](https://s0.wp.com/latex.php?latex=P%5Bx%5D+%3D+%5Csum_%7Bi%7D%5Cbar%7By%7D_i+l_i%5Bx%5D+&bg=ffffff&fg=000&s=0&c=20201002)
at each iteration we can calculate
}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bd%7D%7Bd%5Cbar%7By%7D_i%7D%5Cepsilon+%3D+2+%5Csum_%7Bj+%5Cin+samples%7D%7Bl_i%5Bx_j%5D%28%5Cbar%7By%7D_il_i%5Bx_j%5D-y_j%29%7D+&bg=ffffff&fg=000&s=0&c=20201002)
which returns the gradient we need to step into the next iteration.
F statistics to identify chaotic behavior vs ordered behavior
We then need a metric to figure out if we have a very large cloud of points in each area (which may call for a caotic behavior) or the dependency looks quite good.
One possble approach is to compare wether the variation of the input values (response value) between each section (segment of the input feature) is comparable with the variation within each section.
I have been inspired by F statistics used in ANOVA: we are comparing the variation of the means of each section with the mean of the variations.
![\chi = \frac{E[Var[Y_i]]}{Var[E[Y_i]]}](https://s0.wp.com/latex.php?latex=%5Cchi+%3D+%5Cfrac%7BE%5BVar%5BY_i%5D%5D%7D%7BVar%5BE%5BY_i%5D%5D%7D+&bg=ffffff&fg=000&s=0&c=20201002)
In a ordered behavior we expect the numerator to be quite a lot smaller than the denominator.
An efficent Rust implementation of Lagrange Polynomials
Weights calculation
Pre-calculating baricentral weights reduces the overall computation time.
As these depends only on the nodes they can be stored upfront in a dedicated data structure.

This is a possible implementation in Rust
impl Baricentric { pub fn new(points: & [f64]) -> Baricentric { let weights: Vec<f64> = points .iter() .enumerate() .map(|(i, x0)| { points .iter() .enumerate() .filter(|(j, _)| *j != i) .fold(1.0, |acc, (_, x1)| acc * 1.0 / (*x0 - *x1)) }) .collect(); Baricentric { points: points.to_owned(), weights: weights, } } }
Polar representation of Polynomials
It is possible to represent these polynomials by only listing the poles location and their weight
pub struct PolarPoly{ poles: Vec<f64>, weight: f64 }
Then we may create them by either:
- pass these values directly
- calculate them from a baricentric object: as this contains the information we need for all of the basis, we may want to get each vector individually: this requires an API similar to the vector get method which returns an Option
impl PolarPoly{ pub fn new(poles: & [f64], weight: f64) -> PolarPoly{ PolarPoly{ poles: poles.to_owned(), weight } } pub fn from_baricentric(bar: & Baricentric, i: usize) -> Option<PolarPoly>{ let weight=*(bar.weights.get(i)?); let poles=bar.points .iter() .enumerate() .filter(|(j,_)|{ *j != i }) .map(|(_,(x, _))|{ *x }) .collect(); Some( PolarPoly{ poles, weight } ) } }
Note that each polar polynomial will have a degree equals to
![deg[l_i[x]] = len(nodes) -1](https://s0.wp.com/latex.php?latex=deg%5Bl_i%5Bx%5D%5D+%3D+len%28nodes%29+-1+&bg=ffffff&fg=000&s=0&c=20201002)
The other operations we may want are:
- evaluate the polynomials in a given point of its domain
- transform them into regular polynomials to acquire the whole algebraic operation set and thus calculate a linear combination of the lagrange basis: but this require some more work that is explained in the next section
impl PolarPoly{ pub fn eval(& self, x: f64) -> f64 { self.weight * self.poles .iter() .map(|p| x - p ) .fold(1.0, |acc, val| val * acc) } pub fn to_poly(& self) -> poly.Poly<f64>{ todo!("implement this stuff"); } }
here are two examples of output obtained plotting the basis generated for four poles.
In the first example poles are not equispaced and are placed in 1, 2, 5 and 5.5 . From the grid you may notice how each element of the basis has value 1 in only one pole and 0 in all others 
In the second example there is an equispaced grid, poles are in 1, 2, 3 and 4. 
Connecting with regular Polynomials in Rust
We need an intermediate data structure to efficiently calculate the coefficients
The idea is to recursively multiply all of the components of degree 1; each multiplication is the sum of the current intermediate result times
![P_{i+1}[x] = (x - p_{i+1})P_i[x]](https://s0.wp.com/latex.php?latex=P_%7Bi%2B1%7D%5Bx%5D+%3D+%28x+-+p_%7Bi%2B1%7D%29P_i%5Bx%5D+&bg=ffffff&fg=000&s=0&c=20201002)
![P_{i+1}[x] = x P_i[x] - p_{i+1} P_i[x]](https://s0.wp.com/latex.php?latex=P_%7Bi%2B1%7D%5Bx%5D+%3D+x+P_i%5Bx%5D+-+p_%7Bi%2B1%7D+P_i%5Bx%5D+&bg=ffffff&fg=000&s=0&c=20201002)
by analogy with the binary operation I call the first pass “shift”
![P_{i+1}[x] = shift[P_i[x]] - p_{i+1} P_i[x]](https://s0.wp.com/latex.php?latex=P_%7Bi%2B1%7D%5Bx%5D+%3D+shift%5BP_i%5Bx%5D%5D+-+p_%7Bi%2B1%7D+P_i%5Bx%5D+&bg=ffffff&fg=000&s=0&c=20201002)
This iterative sequence can be made with a fixed size data structure; unfortunately the size is known only at runtime so we may need to use the heap memory.
Iterating on all poles, each iteration will return an intermediate result which will have a degree increased by one: this can be simulated without moving any data but just moving backward the 0th degree coefficient position in the array.
We can start with a constant polynomial equal to 1; this is equivalent to an array of length 1 with just this value: [1]
in the first iteration we will get exactly the first polynomial
![P_{1}[x] = 1 (x - p_1) = x - p_1](https://s0.wp.com/latex.php?latex=P_%7B1%7D%5Bx%5D+%3D+1+%28x+-+p_1%29+%3D+x+-+p_1+&bg=ffffff&fg=000&s=0&c=20201002)
this is equivalent to an array like the following [-p_1, 1]
in the second iteration we have
![P_{2}[x] = (x - p_1)(x - p_2) = x^2 + ((-p_1) + (-p_2)) x + (-p_1) (-p_2)](https://s0.wp.com/latex.php?latex=P_%7B2%7D%5Bx%5D+%3D+%28x+-+p_1%29%28x+-+p_2%29+%3D+x%5E2+%2B+%28%28-p_1%29+%2B+%28-p_2%29%29+x+%2B+%28-p_1%29+%28-p_2%29+&bg=ffffff&fg=000&s=0&c=20201002)
this is equivalent to an array like the following [(-p_1)(-p_2),-p_1-p_2, 1] etc.
The first element is always equal to 1; the others are obtained by subtracting the current value (which is 0 for the lowest cell) with the product of the next cell times the pole.
Once all multiplication have been performed we can multiply all coefficients by the weight.
Now our code looks like this:
pub fn to_poly(& self) -> poly::Poly<f64> { // the polynomial degree should be = to the number of poles // thus the no. of coefficients should be equal to the no. of poles + 1 let degree = self.poles.len(); let mut coeff: Vec<f64> = vec![0.0; 1 + degree]; // the highest coefficient should be equal to 1 coeff[degree] = 1.0; // after each multiplication the degree is increased by one // this can be simulated by counting each iteration backward for (id, pole) in self.poles.iter().enumerate() { for j in (degree - id - 1)..degree { coeff[j] = coeff[j] - coeff[j + 1] * pole; } } // finelly mult by the weight and return poly::Poly::new(coeff.iter().map(|x| self.weight * (*x)).collect()) }
Conclusions
Lagrange polynomials are quite an old tool but are still interesting in modern applications. I mentioned machine learning but another important field is Solomon-Reed error correction codes.
Developing some base structure in Rust has been an interesting journey into the language and optimization.
If you read this far, well I’m impressed! Let me know your comments.

