
Take the (statistical) Test
 Photo by Braden Collum on Unsplash
Photo by Braden Collum on Unsplash
Our trip is finally closing: we visited Jupyter, met Pandas, explored our datasets, created independent scripts and introduced linear regression.
Now is the time to introduce a few statistical tests
The jupyter notebooks for this series of posts, the datasets, their source and their attribution are available in this Github Repo
Statistical Tests Intro
The purpose of this section is merely to introduce a couple of the most common statistical test.
There is no attempt to give a complete statistical background; there is no attempt to give any complete list of available tests.
The main purpose is to illustrate a typical usage of some of the most common python libraries when performing some more complex analysis.
The reader is invited to study the statistical theory before using any test in order to familiarize with names, objectives and common pitfalls.
Bivariate Student’s T test
We may want to verify if two sample datasets may be coming from the same distribution or different ones, i.e. they are not very different or they are different enough.
This test makes some assumptions (e.g. the distribution is normal etc.) please check the details before using this test
This test’s hypothesis are the following:
- H0 (base hypothesis) both datasets are coming from a sampling of the same distribution
- H1 (alternative hypothesis) the datasets may have been sampled out of different distributions
In this example we are going to compare the distribution of temperatures measured in Rome in June 1951 with the those measured in June 2009 and try to see if there is any meaningful shift
import pandas as pd import seaborn as sns import scipy.stats from scipy.stats import ttest_ind
read daily temperatures measured in Rome from 1951 to 2009
This is the content:
| column | meaning |
|---|---|
| SOUID | categorical: measurement source id |
| DATE | calendar day in YYYYMMDD format |
| TG | average temperature |
| Q_TG | categorical: quality tag 9=invalid |
roma = pd.read_csv("TG_SOUID100860.txt",skiprows=20)
This dataset column names include spaces, we need to remove them
roma.columns = list(map(str.strip,roma.columns))
roma.columns
Index(['SOUID', 'DATE', 'TG', 'Q_TG'], dtype='object')
let’s parse the DATE field into a pandas date series
roma.DATE = pd.to_datetime(roma.DATE,format="%Y%m%d")
We can now safely extract month and year
roma["MONTH"] = roma.DATE.dt.month
roma["YEAR"] = roma.DATE.dt.year
Let’s clean the dataset from invalid measurements
roma_cleaned = roma.loc[roma.Q_TG != 9,:]
Now I will extract the two datasets to compare
roma_giugno_1951 = roma_cleaned.loc[ (roma_cleaned.YEAR == 1951) & (roma_cleaned.MONTH == 6), "TG" ]
roma_giugno_2009 = roma_cleaned.loc[ (roma_cleaned.YEAR == 2009) & (roma_cleaned.MONTH == 6), "TG" ]
ttest_ind(roma_giugno_1951,roma_giugno_2009)
TtestResult(statistic=np.float64(-2.167425930725216), pvalue=np.float64(0.03432071944797424), df=np.float64(58.0))
p-value is about 3% this is not a scientific proof of temperature shift but some more investigations may be worth
roma_giugno= roma_cleaned.loc[ ((roma_cleaned.YEAR == 2009) | (roma_cleaned.YEAR == 1951)) & (roma_cleaned.MONTH == 6) ] sns.kdeplot(data=roma_giugno,x="TG",hue="YEAR")
<Axes: xlabel='TG', ylabel='Density'>

ANalyisis Of VAriance
Analysis of Variance is a family of methodologies that extend Student’s T to more than two groups; their goal is to prove whether a factor makes a difference when it splits a set of measurements.
It can be used to show if a disease treatment is effective or not. The factor or categorical independend variable is the “input”, while the health parameter is a continuous dependent variable or “output”.
We are going to show the simplest use of it called Fixed Mixture
In our exercise we are going to show the relevance of geography, year or gender respect to the unemployment in Italy for people between 15 and 24
unemployment = pd.read_csv( "unemployment_it.csv", dtype={ "Gender":"category", "Area":"category", "Age":"category", } ) unemployment.columns
Index(['Age', 'Gender', 'Area', 'Frequency', 'Year', 'Rate'], dtype='object')
unemployment.Gender.unique()
['Male', 'Female'] Categories (2, object): ['Female', 'Male']
unemployment.Area.unique()
['North', 'North-west', 'North-east', 'Center', 'South'] Categories (5, object): ['Center', 'North', 'North-east', 'North-west', 'South']
import statsmodels.api as sm
from statsmodels.formula.api import ols
Using * in the formula is adding interaction between factor in the analysis
model = ols('Rate ~ Gender * Area * Year', data=unemployment).fit()
table = sm.stats.anova_lm(model, typ=2)
print(table)
sum_sq df F PR(>F)
Gender 1285.245000 1.0 31.770447 6.601688e-08
Area 18194.797505 4.0 112.440984 7.299258e-48
Gender:Area 93.451500 4.0 0.577516 6.793006e-01
Year 1134.738195 1.0 28.050014 3.420439e-07
Gender:Year 20.187814 1.0 0.499030 4.808400e-01
Area:Year 15.967523 4.0 0.098677 9.827658e-01
Gender:Area:Year 40.068551 4.0 0.247617 9.108217e-01
Residual 7281.738917 180.0 NaN NaN
The geographical area looks very important respect to the others: the F score is much higher and the p-value is way smaller than any other contributor
import seaborn as sns
sns.kdeplot(data=unemployment,x="Rate",hue="Gender")
<Axes: xlabel='Rate', ylabel='Density'>

sns.kdeplot(data=unemployment,x="Rate",hue="Area")
<Axes: xlabel='Rate', ylabel='Density'>

Many examples are available on the internet, e.g. this one
(Optional) How it works
The main idea is to see how a grouping is or not relevant to explain the global variance
In order to understand this test we can derive a formula representing the contribution to the global variance given by each the variance within each subgroup and the variance between all subgroups
Let’s start with the usual variance definition
![var[X] := \frac{\sum_{x \in X}{(x - \bar{x})^2}}{n - 1}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bx+%5Cin+X%7D%7B%28x+-+%5Cbar%7Bx%7D%29%5E2%7D%7D%7Bn+-+1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
where ![\bar{x} = E[X] = \frac{\sum_{x \in X}x}{card[X]}](https://s0.wp.com/latex.php?latex=%5Cbar%7Bx%7D+%3D+E%5BX%5D+%3D+%5Cfrac%7B%5Csum_%7Bx+%5Cin+X%7Dx%7D%7Bcard%5BX%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
given a partition 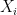

![n = card[X]](https://s0.wp.com/latex.php?latex=n+%3D+card%5BX%5D&bg=ffffff&fg=000&s=0&c=20201002)
![n_i = card[X_i]](https://s0.wp.com/latex.php?latex=n_i+%3D+card%5BX_i%5D&bg=ffffff&fg=000&s=0&c=20201002)
so ![\bar{x_i} = E[X_i] = \frac{\sum_{x \in X_i}x}{n_i}](https://s0.wp.com/latex.php?latex=%5Cbar%7Bx_i%7D+%3D+E%5BX_i%5D+%3D+%5Cfrac%7B%5Csum_%7Bx+%5Cin+X_i%7Dx%7D%7Bn_i%7D&bg=ffffff&fg=000&s=0&c=20201002)
breaking the sum into each subgroup and adding and removing 
![var[X] := \frac{\sum_{i \in G}{\sum_{x \in X_i}(x - \bar{x} + \bar{x_i} - \bar{x_i})^2}}{n - 1}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B%5Csum_%7Bx+%5Cin+X_i%7D%28x+-+%5Cbar%7Bx%7D+%2B+%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx_i%7D%29%5E2%7D%7D%7Bn+-+1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
developing the square
![var[X] := \frac{\sum_{i \in G}{\sum_{x \in X_i}(x - \bar{x_i})^2 + (\bar{x_i} - \bar{x})^2 -2(x - \bar{x_i})(\bar{x_i} - \bar{x})}}{n - 1}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B%5Csum_%7Bx+%5Cin+X_i%7D%28x+-+%5Cbar%7Bx_i%7D%29%5E2+%2B+%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5E2+-2%28x+-+%5Cbar%7Bx_i%7D%29%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%7D%7D%7Bn+-+1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
we can bring the constant part outside of the sum
![var[X] := \frac{\sum_{i \in G}{( n_i (\bar{x_i} - \bar{x})^2 + \sum_{x \in X_i}(x - \bar{x_i})^2 -2(\bar{x_i} - \bar{x})\sum_{x \in X_i}{(x - \bar{x_i})}})}{n - 1}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B%28+n_i+%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5E2+%2B+%5Csum_%7Bx+%5Cin+X_i%7D%28x+-+%5Cbar%7Bx_i%7D%29%5E2+-2%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5Csum_%7Bx+%5Cin+X_i%7D%7B%28x+-+%5Cbar%7Bx_i%7D%29%7D%7D%29%7D%7Bn+-+1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
by definition of 

so the last addend can be simplified; let’s break the fraction
![var[X] := \frac{\sum_{i \in G}{ n_i (\bar{x_i} - \bar{x})^2 }}{n - 1} + \frac{\sum_{i \in G}{\sum_{x \in X_i}(x - \bar{x_i})^2}}{n - 1}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B+n_i+%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5E2+%7D%7D%7Bn+-+1%7D+%2B+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B%5Csum_%7Bx+%5Cin+X_i%7D%28x+-+%5Cbar%7Bx_i%7D%29%5E2%7D%7D%7Bn+-+1%7D+&bg=ffffff&fg=000&s=0&c=20201002)
now we multiply and divide the second part by 
![var[X] := \frac{\sum_{i \in G}{ n_i (\bar{x_i} - \bar{x})^2 }}{n - 1} + \sum_{i \in G}{\frac{(n_i - 1)}{n -1}\frac{\sum_{x \in X_i}(x - \bar{x_i})^2}{n_i - 1}}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B+n_i+%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5E2+%7D%7D%7Bn+-+1%7D+%2B+%5Csum_%7Bi+%5Cin+G%7D%7B%5Cfrac%7B%28n_i+-+1%29%7D%7Bn+-1%7D%5Cfrac%7B%5Csum_%7Bx+%5Cin+X_i%7D%28x+-+%5Cbar%7Bx_i%7D%29%5E2%7D%7Bn_i+-+1%7D%7D+&bg=ffffff&fg=000&s=0&c=20201002)
now we can show the variance of each subgroup
![var[X] := \frac{\sum_{i \in G}{ n_i (\bar{x_i} - \bar{x})^2 }}{n - 1} + \sum_{i \in G}{\frac{(n_i - 1)}{n -1}var[X_i]}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+%5Cfrac%7B%5Csum_%7Bi+%5Cin+G%7D%7B+n_i+%28%5Cbar%7Bx_i%7D+-+%5Cbar%7Bx%7D%29%5E2+%7D%7D%7Bn+-+1%7D+%2B+%5Csum_%7Bi+%5Cin+G%7D%7B%5Cfrac%7B%28n_i+-+1%29%7D%7Bn+-1%7Dvar%5BX_i%5D%7D+&bg=ffffff&fg=000&s=0&c=20201002)
both addends are weighted; this is equivalent to
![var[X] := var[E[X_i]] + E[var[X_i]]](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3A%3D+var%5BE%5BX_i%5D%5D+%2B+E%5Bvar%5BX_i%5D%5D+&bg=ffffff&fg=000&s=0&c=20201002)
we can rewrite it by using the “variance within groups” and “variance between groups” usual names
![var[X] = var_{between} + var_{within}](https://s0.wp.com/latex.php?latex=var%5BX%5D+%3D+var_%7Bbetween%7D+%2B+var_%7Bwithin%7D+&bg=ffffff&fg=000&s=0&c=20201002)
The F-Score is calculated as the ratio of these two components:



