
Embedding a (binary) Tree

Photo by Rutpratheep Nilpechr on Unsplash
In this post I will show how to create a binary tree in Rust language, which is suitable to be used in embedded devices
Here is the journey so far; I will mention some of the concepts already described in these posts.
The code for this post is here.
So far we created and explored trees which grow into the application heap memory, this allowed us to have almost arbitrary size and use the type system to guarantee consistent states
What if we cannot use the heap? This happens in some “embedded” devices, which are an important target of Rust.
Our trees will have a maximum height (or depth using mainstream jargon) and this may seem a hard limitation, but has interesting cases in machine learning.
To simulate this case we are going to add the following line at the beginning of our file
#![no_std]
This completely disable any access to the heap, as well as other libraries which may not work on bare metal platforms.
Let’s dive in.
Choosing compromises

Photo by Egor Myznik on Unsplash
When developing code we may have constraints of memory size, execution time, storage size, I/O throughput, computation cores available.
Dealing with these constraints may require to give up perfect solutions and use some approximations; choosing carefully these approximations and account for the errors we expect is a critical path of a software architecture.
Size compromise
By forcing our data structure to work in the stack we need to know its size in advance thus:
- we may allocate more space than needed
- we may not grow over the maximum size we define
Type compromise
A more subtle point is we may accept that types can’t fully describe our status, i.e. our data structure may allow for inconsistent states.
To deal with this point we have two tools:
- incapsulate the inner elements of our data structure so that they can be accessed only via our interface
- add unit tests to verify if the interface respect the “contract”
Error management compromise
What if our data structure ends up in an inconsistent state?
We may have e.g.:
- incomplete coverage of our tests
- hardware failure
- software/hardare attacks (e.g. rowhammer)
If one of these or any other failure brings our data structure in an inconsistent state, we have two options:
- panic i.e. terminate the program
- return a Result type
The first solution is simpler but makes it impossible to understand the reasons of the failure in a post-mortem analysis, moreover if I’m developing a library I may prefer to leave the decision about how to handle the inconsistent state to the application.
Addressing a binary tree in an array
We can put a binary tree in a fixed size array if we store the data in a certain order.
Let’s take our previous example of a sorting tree and suppose to insert the following values
- 4
- 6
- 2
- 3
- 5
- 1
- 8
This is how our tree would look like: remember that smaller values get are placed in the right branch and higher are placed in the left branch.

Now suppose to call the root #1: we are going to label all nodes with positive integers with the following rules:
- the right node label number is twice than the parent node label number
- the left node label number is equal twice the parent node label plus one
Here is the result

This rule allows to map a binary tree into an array
| #1 | #2 | #3 | #4 | #5 | #6 | #7 |
|---|---|---|---|---|---|---|
| (4) | (2) | (6) | (1) | (3) | (5) | (8) |
It is no coincidence that this tree has 3 “levels” and the number of values it can host is equal to 
So using this address rule we can use an array with a fixed lenght of 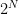

Option<T> objects.
For simplicty we have this T type to implement Copy so we can return it by value. The height of our tree (more commonly referred as depth) will be calculated as 
In this example we decide to fix the maximum depth to 8 so our tree will be placed into an array of 
struct STree8<T>{ nodes: [Option<T>;256] } impl<T : Copy> STree8<T>{ // create an empty tree fn new() -> STree8<T>{ STree8{ nodes: [None; 256] } } // calculate the tree depth fn depth(& self) -> u32{ let mut result : usize = 0; // find the highest index of a non empty cell // there is no check about the array integrity here for (i, value) in self.nodes.into_iter().enumerate(){ if let Some(_) = value{ if i > result{ result = i; } } } // the cell 0 is always ignored with our assignment if result == 0 { return 0; } result.ilog2() + 1 } // this function returns the content of a cell // but checks that the index is below the maximum allowed: // we can't afford panic in an embedded code // error types are explained later on fn peek(& self, cell: usize) -> Result<Option<T>,TreeError>{ if cell >= 256{ return Err(TreeError::TreeOverflowCell) } Ok(self.nodes[cell]) } }
With our labelling rule we can create a sorting tree provided the type T implements the Ord trait
trait SortTree<T : Ord>{ fn insert(& mut self, value: T) -> Result<usize, & 'static str>; } impl<T : Ord> SortTree<T> for STree8<T>{ fn insert(& mut self, value: T) -> Result<usize, & 'static str>{ let mut node : usize = 1; loop { if node > 255{ return Err("level greater than 8") } match self.nodes[node]{ None => { self.nodes[node] = Some(value); return Ok(node); } Some(ref node_value) => { // if we have the value in the tree already // then stop if value == *node_value{ return Ok(node); } // the shift 1 operation is equivalent // to multiply by 2 node <<= 1; if value > *node_value{ // if the value is greater than // the one in the current cell // go to the "left" node node += 1; } } } } } }
We can now test our insert and depth methods
mod tests{ use super::*; #[test] fn can_insert(){ let mut tree : STree8<i64> = STree8::new(); let test_list = [4,5,2,8,6,1]; let mut count = 0; for value in test_list{ let result = tree.insert(value); match result { Err(message) => { panic!("failed insertion {}",message); }, Ok(node) => { assert!(node < 256); count += 1; } } } assert_eq!(count,test_list.len()); let result = tree.peek(1); assert_eq!(Ok(Some(4)),result); let result = tree.peek(2); assert_eq!(Ok(Some(2)),result); let result = tree.peek(3); assert_eq!(Ok(Some(5)),result); } #[test] fn test_depth(){ let mut tree : STree8<i64> = STree8::new(); assert_eq!(tree.depth(),0); let _ = tree.insert(4); assert_eq!(tree.depth(),1); let _ = tree.insert(5); assert_eq!(tree.depth(),2); let _ = tree.insert(2); assert_eq!(tree.depth(),2); let _ = tree.insert(8); assert_eq!(tree.depth(),3); let _ = tree.insert(6); assert_eq!(tree.depth(),4); let _ = tree.insert(1); assert_eq!(tree.depth(),4); } }
Design a Depth First Traversal Iterator
As in Climbing a (binary) Tree post we need a stack structure to store
- the return address
- the node we are currently exploring
Storing the current node
In a previous post ( Stacking Bits ) I described how to create a stack of boolean using shift operators on a usize word.
it turns out that is exactly working as our address rule – and this is not a coincidence: we already saw how trees and stacks are mutually connected.
By masking the topmost bit this the state is representing the exact address od our array cell. The following methods are extracted from the extended implementation.
pub fn size(& self) -> u32 { usize::BITS - usize::leading_zeros(self.stack) - 1 } pub fn get_state(& self) -> usize { self.stack ^ (1 << self.size()) }
by placing the binary stack code into a different file btree.rs we can access it using module commands in our main library lib.rs
mod bstack;
Storing the return address
As we cannot use a flexible data structure like Vec<T> to store the return address we may leverage the stack property to create an array to store it in the same index of each traversed cell
Thus our iterator structure looks like this:
struct STree8Iter<'a, T>{ tree: & 'a STree8<T>, stack: bstack::BStack, addresses: [Option<Address>; 256] }
Before implementing it we make a little dirgression about errors
Managing errors

Photo by Kenny Eliason on Unsplash
We cannot use String object to represent an error value, due to our heap constraint.
As we saw that & str objects in the stack do not live enough we may choose to use constant strings which have infinite lifetime & 'static str but this has three drawbacks:
- we cannot add dynamic information about why and how the system failed
- this will make it more complex for the users of our library to match and handle errors
- this may require more space than using other solutions
A common approach is to define an enum which describes the expected failure modes. As we are using another library (bstack) which has its own errors it is a common practice to create one enumeration case also including the error type from this library
#[derive(Debug, Clone, Copy, PartialEq)] enum TreeError{ MissingReturnAddress(usize), StackError(bstack::BStackError), IteratorCompleted, TreeOverflowCell }
Rust has a very nice way to manage the error monad which include some syntax sugar like using a question mark at the end of an expression.
The std crate defines also an Error trait, which I will ignore in this specific case because:
- in our emebedded environment may not work
- I need to keep this post simple
To use this shortcut when we call a method from bstack library (which may return a different kind of error respect to our current signature) we need some kind of automatic translation. This can be done implementing the From trait.
In our case we will just wrap the bstack error in our TreeError variant:
impl From<bstack::BStackError> for TreeError{ fn from(value: bstack::BStackError) -> Self { TreeError::StackError(value) } }
This method is suitable for small applications like this one: more complex libraries are available for larger projects e.g. thiserror
Implement the Depth First Traversal Iterator
In a previous post I explained how to create an iterator for a binary tree: here we are going to implement the same sequence using our different stack structure.
Here is the address enumeration described there:
#[derive(Debug, Clone, Copy, PartialEq)] enum Address{ Enter, AfterLeft, ValueYielded, Completed }
To make paths more explicit I decided to use an enumeration to represent the possible connections from a node:
#[derive(Debug, Clone, Copy, PartialEq)] enum Branch{ Left, Right }
The first step is to incapsulate the push and pop calls to avoid misalignments: in this case there are two push methods
push_branchto describe when accessing a chidren node with a relative path (i.e. left or right) from the currentpush_cellis used to push a node with an absolute path, usually when a parent node is pushed back into the call stack with a changed return address
impl<'a, T : Copy> STree8Iter<'a, T>{ pub fn new(tree : & 'a STree8<T>) -> STree8Iter<'a, T>{ let mut iterator = STree8Iter::<'a, T>{ tree, stack: bstack::BStack::new(), addresses: [None; 256] }; // prepare the stack if the tree has a root node if let Ok(Some(_)) = iterator.tree.peek(1) { // ignore errors as iterator is just created let _ = iterator.push_branch(Branch::Right, Address::Enter); } iterator } // relative access from the current node fn push_branch(& mut self, branch: Branch, address: Address) -> Result<usize, TreeError>{ let _ = self.stack.push(branch == Branch::Right)?; let cell = self.stack.get_state(); self.addresses[self.stack.get_state()] = Some(address); Ok(cell) } // used to push back parent nodes in the call stack // when we need to change their return address fn push_cell(& mut self, cell: usize, address: Address) -> Result<usize,TreeError>{ let _ = self.stack.push(cell & 1 == 1)?; let cell = self.stack.get_state(); self.addresses[self.stack.get_state()] = Some(address); Ok(cell) } fn pop(& mut self) -> Result<(usize, Address), TreeError> { let cell = self.stack.get_state(); let _branch = self.stack.pop()?; let address = self.addresses[cell].ok_or(TreeError::MissingReturnAddress(cell))?; Ok((cell, address)) } pub fn next_item(& mut self) -> Result<T, TreeError>{ todo!("to be developed"); } }
Finally where we have the actual implementation of next_item, which works in the same way we implemented it in the heap based tree.
pub fn next_item(& mut self) -> Result<T, TreeError>{ while self.stack.size() > 0{ let (cell, address) = self.pop()?; match address{ Address::Enter => { let left_address = cell << 1; match self.tree.peek(left_address)?{ None => { self.push_cell(cell, Address::AfterLeft)?; } Some(_) =>{ self.push_cell(cell, Address::AfterLeft)?; self.push_branch(Branch::Left, Address::Enter)?; } } }, Address::AfterLeft => { self.push_cell(cell, Address::ValueYielded)?; if let Some(ref result) = self.tree.peek(cell)?{ return Ok(*result); }else{ return Err(TreeError::IteratorCompleted) } }, Address::ValueYielded => { let right_address = (cell << 1) | 1; match self.tree.peek(right_address)?{ None => { self.push_cell(cell, Address::Completed)?; }, Some(_) => { self.push_cell(cell, Address::Completed)?; self.push_branch(Branch::Right, Address::Enter)?; } } }, Address::Completed =>{ } } } Err(TreeError::IteratorCompleted) }
Debugging
We may not have a debugger easily running in a bare metal platform; moreover we have no print! macro available and also writing results on the serial connection with the host may alter the platform behavior.
You certainly noticed that the next_item implementation does not conform the iterator trait this time. Of course we can create one anyway.
impl<'a, T : Copy> Iterator for STree8Iter<'a, T>{ type Item = T; fn next(& mut self) -> Option<Self::Item> { // WARNING // this implicitly discard any error self.next_item().ok() } }
While next_node provides a rich return type explaining failures (mostly useful for debugging), this implementation removes all failure information to gain the rich Iterator echosystem: the library user is free to chose wathever is more appropriate.
A test suite is not solving all bare metal issues but may help when possible, to solve issues in a frendlier environment
#[cfg(test)] mod tests{ use super::*; #[test] fn can_create_iterator(){ let mut tree : STree8<i64> = STree8::new(); let test_list = [4,5,2,8,6,1]; for value in test_list{ let _result = tree.insert(value); } let mut iterator = STree8Iter::new(& tree); assert_eq!(iterator.stack.size(),1); assert_eq!(iterator.pop(),Ok((1,Address::Enter))); } #[test] fn can_extract_with_next_item(){ let mut tree : STree8<i64> = STree8::new(); let test_list = [4,5,2,8,6,1]; for value in test_list{ let _result = tree.insert(value); } let mut iterator = STree8Iter::new(& tree); let mut result = iterator.next_item(); assert_eq!(Ok(1),result); result = iterator.next_item(); assert_eq!(Ok(2),result); } #[test] fn sort_works(){ let mut tree : STree8<i64> = STree8::new(); let test_list = [4,5,2,8,6,1]; for value in test_list{ let _result = tree.insert(value); } let expected = [1,2,4,5,6,8]; let mut count = 0; for (i,v) in tree.into_iter().enumerate(){ assert_eq!(v,expected[i]); count += 1; } assert_eq!(count,test_list.len()); } }
Conclusions
Rust allows pretty complex abstractions to run on bare metal with very little or no runtime cost (iterators are a well known example).


